Operating System Basic Notes
OS Definition
操作系统是一个大型的程序系统, 它负责(处理机管理, 存储管理, 设备管理, 文件系统):
- 计算机系统软、硬件资源的分配和使用
- 控制和协调并发活动
- 提供用户接口, 使用户获得良好的工作环境
GCC 内联汇编
asm ( assembler template // assembly language
:=output operands // 约定输出
:input operands // 约定输入
:clobbers // 约定插入
);
constraints:
- m/v/o = memory
- r = register
- Q = ea/b/c/dx
- a = eax
- b = ebx
- c = ecx
- d = edx
- D = edi
- S = esi
- 0/n = first/nth constraints
基本概念
操作系统的特性
- 并发性 : 能处理多个同时性活动的能力
- 共享性 : 多个计算任务对系统资源的共同享用
- 不确定性: 操作系统能处理随机发生的多个事件 - 程序运行次序的不确定性, 程序运行时间的不确定性
操作系统的资源管理功能
处理器调度
- 确定进程调度策略
- 给出进程调度算法
- 进行处理机的分派
存储器管理
- 存储分配与存储无关性
为用户提供逻辑地址, 解决主存分配问题
- 存储保护
实现系统程序与用户程序之间的隔离, 实现不同用户程序之间的隔离
- 存储扩充
虚拟内存管理: 主存+磁盘, 为每个进程管理一个虚拟内存映射链表
设备管理
- 设备无关性
用户向系统申请和使用的设备无关实际操作的设备, 操作系统为用户提供统一的逻辑设备(名)
- 设备分配(独享分配/共享分配/虚拟分配)
- 设备的传输控制(设备启动处理, 设备中断处理, 设备结束处理)
组织设备完成 I/O 操作, 并正确处理中断
文件资源管理
为用户提供一种简便、统一的存取和管理信息的方法, 解决信息的共享/数据的存取控制/数据的保密等问题:
- 实现用户的信息组织
- 提供存取方法
- 实现文件共享
- 保证文件安全
- 保证文件完整性
- 完成磁盘空间分配
操作系统的演变
- 单用户系统(45-55) -> 批处理系统(55-65) -> 多道系统(65-80) -> 分时系统(70-) -> 分布式系统
- 手工系统 -人机矛盾-> 联机批处理系统 -CPU I/O 矛盾 -> 脱机批处理系统 -响应能力-> 执行系统(中断/通道) -并行-> 多道批处理系统(粗粒度) -> 分时系统(细粒度) -> 实时系统 -> 个人/网络/分布式系统
批处理系统
作业成批送入计算机, 然后由作业调度程序自动选择作业, 在系统内(多道)运行
- 系统吞吐率高: 脱机/多道运行
- 作业周转时间长, 用户使用不方便, 缺少交互性
分时系统
采用时间片(time slice)轮转(round robin)的方法, 使计算机同时为多个终端用户服务, 保证对每个用户都有足够快的响应时间, 并提供交互会话功能
- 并行性
- 独占性
- 交互性
单处理器系统: 处理器与设备/处理器与通道/通道与通道/设备与设备可以同时刻并行(真正意义上的同时进行)
实时系统
实时系统对外部输入的信息, 能够在规定时间内处理完毕并作出反应(实时控制/实时信息处理) e.g 嵌入式操作系统
- 可靠性
- 安全性
- 及时响应
操作系统虚拟机
- 在裸机上配置了操作系统后便构成了操作系统虚拟机
- 裸机的指令系统: 机器指令; 操作系统虚拟机的指令系统: 系统调用
用户接口
- 操作/命令接口(操作命令): 作业控制语言/键盘命令(CLI)/图形化用户界面(GUI)
- 程序接口(系统功能调用): 在用户程序中可以直接使用系统功能调用(system call)请求操作系统提供的服务
操作系统的组织结构
- 一体化结构
- 模块化结构
- 可扩展内核(微内核)结构
- 层次化结构
并发
Concurrent
程序并发的特点
- 程序执行的间断性
- 相互通信的可能性
- 资源分配的动态性
启动
BIOS
- 基本输入输出程序
- 系统设置信息
- 开机后自检程序
- 系统自启动程序
启动顺序
寄存器
- CF: 初值 F000H
- EIP: 初值 FFF0H
(FFF)F0000H+FFF0H = FFFFFFF0H, BIOS 的 EPROM(Erasable Programmable Read Only Memory) 处 加电后第一条指令一般是 ljmp(实模式下, 内存 !MB), 跳转地址为 CF<<4+EIP, 跳转至 BIOS 例行程序起始点.
BIOS Config
BIOS 根据设置(硬盘/U 盘/网络启动), 加载存储设备的主引导扇区(Master Boot Record)(第一个扇区)的 512 字节至内存 0x7c00 处, 开始执行第一条指令(Boot Loader)
Boot Loader
实模式与保护模式带来的问题:
- 在实模式的寻址模式中, 令物理地址为 16 位段寄存器左移 4 位加 16 位逻辑地址的偏移所得的 20 位地址
- 若要访问 1MB 之后的内存, 则必须开启 A20 Line 开关(关闭 wrap around), 将 32 位地址总线打开, 并进入保护模式(Protect Mode)
- 在实模式中, 0~4KB 为中断向量表保留, 640KB ~ 1MB 为显存与 BIOS 保留, 实际可用的内存只有 636KB
- 考虑到日后内核镜像的体积有超过 1MB 的可能, 所以将其装载到物理地址 1MB(0x100000) 之后连续的一块内存中更好.
- 若要装载内核到物理地址 1MB 之后(实模式下无法访问), 可在实模式中暂时将其装载到一个临时位置, 待进入保护模式之后再移动至合适位置
解决方案:
- 将内核镜像装入内存临时地址
- 开启保护模式
- 移动内核镜像至 1MB 之后合适位置
- 跳转至内核入口(
jmp addr用以修改 cs:eip)
标志
lab1/tools/sign.c:
- 有效字节小于 510 bytes
- 结尾为 0x55aa
- 总计字节小于 512 bytes
基本功能
- 切换到保护模式, 启动段机制
- 通过 8042 键盘控制器的端口, 开启 A20, 关闭 memory wrap around, 获取足够内存空间
; 键盘控制器的命令
; 0xD0 Read Output Port
; 0xD1 Write Output Port
; 0xDD Enable A20 Address Line
; 0xDF Disable A20 Address Line
; 0x60 - 数据端口, 0x64 - 命令端口
call empty_8042
mov al,0xd1
out 0x64,al
call empty_8042
mov al,0xdf
out 0x60,al
call empty_8042
empty_8042:
dw 00ebh, 00ebh
in al,64h
test al,2
jnz empty_8042
ret
置 cr0 保护模式标志位(bit0) 为 1
加载全局描述符表
设置各个通用寄存器与段寄存器
从硬盘上加载 某种(kernel in ELF) 格式的 os kernel(在硬盘中紧邻 MBR) 至内存的固定区域
跳转到 os kernel 的入口点(entry point), 转移控制权至 os
保护模式与段机制
- CS -> 全局描述符表(其起始地址与表大小位于 gdt 寄存器中)某项(每项存有 base/limit 等信息) -> 局部描述符表 -> 段选择子(段的基本信息) -> 基址+EIP -> 线性地址 ---页机制---> 物理地址
- 将 cr0 寄存器 bit0 置为 1, 表示进入了保护模式, 段机制开始起作用
物理内存管理
Boot Loader 探测机器内存分布
为内存管理模块提供基础: 在进入实模式前, 调用 int 15h(88h, e801h, e820h), 借助 BIOS 中断获取内存信息
Boot Loader 基本概念
Boot Loader 基本目标
- 抽象: 逻辑地址空间(线性物理地址映射)
- 保护: 独立地址空间(进程间互不影响)
- 共享: 访问相同内存(内核空间与共享库)
- 虚拟化: 独占内存空间假象
基本管理方式
- 重定位(relocation)
- 分段(segmentation): 代码段/数据段
- 分页(paging)
- 虚拟存储(virtual memory): 内存视作硬盘的缓存, 硬盘视作虚拟内存
地址生成
地址生成时机
- 编译时
- 链接时
- 加载时
- 执行时(相对寻址)
地址映射
软硬件结合:
逻辑地址 ---> 物理地址
- 硬件(CPU/MMU)完成映射地址
- 操作系统建立映射规则(页表)
地址检查
软硬件结合:
- 操作系统设置的段机制和段长度
- 硬件(CPU/MMU)根据段信息进行地址检查(内存访问是否异常)
连续内存分配
- malloc
- free
内存碎片
- 外部碎片: 已分配单元间无法利用空闲单元(请求内存单元过大)
- 内部碎片: 已分配单元内空闲单元
动态分配策略
- Fist-fit(最先匹配): 使用第一个可利用空闲块 - 容易产生外部碎片, 分配大块效率低
- Best-fit(最佳匹配): 使用利用度最高的空闲块 - 外部碎片过小, 释放时需重新排列空闲块链表(升序)
- Worst-fit(最差匹配): 使用利用度最差的空闲块 - 分配中块效率高, 释放时需重新排列空闲块链表(降序)
碎片整理策略
ucore 实现
- 连续存放 n 个 page 结构, 形式表示内存页, 并在连续内存块的首页(header page)保存此连续块的连续页数目
- 维护一个链表, 链表每项为大块连续内存块的起始页(header page address) 和 连续页数目, 管理分散的连续内存块
紧凑
Compaction, 将不同进程占用内存单元移至较为集中的地方:
- 只可移动 可动态重定位程序
- 只可移动 等待状态进程
分区对换
Swapping In and Swapping Out:
将等待状态进程的分区对换至外存,以增大可用内存单元
e.g Linux Swap 分区: 安装系统时一般切割大小为内存大小的 50%~100% 的外存作为 Swap 分区
Malloc 实现策略
启发式编程
Heuristic Programming:
- 建立已分配 void 指针表,free 函数执行时,只回收表中存在的指针;不存在则报错
- 对 heap 进行分区 - 小/中/大块内存请求,分别从不同区域(8/16/32 最小单位区)分配
- 记录当前堆块的信息,如长度,空闲状态
- 记录周围环境信息,如保留上/下一堆块的指针或记录上/下堆块空闲状态
伙伴系统
Buddy System:
- 可分配内存单元总大小为 2^n
- 总是将大小 小于请求大小的2 倍且为2 的幂次方 的某块内存单元分配出去(大小为 2^(i-1))
合并空闲块
- 空闲块相邻
- 空闲块等大
- 低地址空闲块的 起始地址 必须为 空闲块大小 的 2 的幂次方倍(2 倍以上)
非连续内存分配
- 支持一个程序使用非连续的物理地址空间
- 支持共享代码与数据
- 支持动态加载与动态链接
段式存储管理
将逻辑地址划分, 低位表示段内偏移, 高位(取摸)表示段号(类比缓存中的内存地址)
GDT
typedef struct gdt_ptr {
uint16_t gdt_limit; // gdt_length - 1
uint32_t gdt_base;
} __attribute__((packed)) gdt_ptr_t;
- 用 16 位来表示表的长度(2 ^ 16 = 65532 bytes), 除以每一个描述符的 8 字节, 最多能创建 8192 个描述符
页式存储管理
开启页机制:
- init page directory(首址位于 cr3 寄存器), page table
- update GDT
- update ds,es,ss
- update cs with jmp instruction
- cr0 寄存器 bit31(most bit) 置 1
虚拟地址
TLB (Translation Lookaside Buffer in CPU/PM):
- Virtual Address =
2^(bits of virtual page offset) * virtual page number + virtual page offset. - VA = VPN (virtual page number point to PPN) + VPO(virtual page offset = PPO).
- 根据 VPN 在页表中找到对应表项(VPN 表示项号), 每项保存着 PPN.
- TLB = TLBT (tag) + TLBI(index) + VPO.
- 因为内存局部性原理, TLB 一般只需要很小 (比如 64 项) 即可达到不错的效果.
物理地址
C(cache) PPO = VPO:
- Page Frame (帧): 高位为帧号, 低位为偏移.
- Physical Address =
2^(bits of phy page offset) * phy page/frame frame number + phy page offset - PA = PPN (physical page number) + PPO (physical page offset = VPO).
- CA = CT(tag) + CI(index) + CO(offset).
页表
- 页表由操作系统建立, 硬件(CPU/MMU)根据页表信息将虚拟地址映射为物理地址
页表结构
- FN/PPN
- 标志位: resident bit(存在位)/dirty bit(修改位)/reference(clock) bit(引用位)
性能问题
- 两次访存: 第一次获取页表项, 第二次访问实际数据
- 页表占据大量内存单元
TLB
Translation Lookaside Buffer:
缓存页表项 - key: VPN, value: PPN 不用访问页表
多级页表
- 切割页表: 建立子页表
- Page Directory -> Page Table -> Physical Address
- 将线性地址分成三部分 Directory+Table+Offset: cr3+Dir 取出 page table base, ptb+Tab 取出 physical address base, pab+offset = pa
CR3 寄存器: 保存一级页表的基址
- 父页表表项保存子页表起始地址, 逻辑地址某部分保存偏移地址(子表项号)
- 存在位为 0 时, 不用保存子表, 节省内存单元
反置页表
- PPN 作为页表索引, 页表项保存 VPN(或者 Hash(VPN|PID))
- 将 VPN 映射为 PPN 时, 需遍历整个页表(但此页表只占用少量内存单元)
段页式存储管理
在页式存储管理基础上, 引入段式存储管理
<--- vsn --- vpn --- vpo ---> 映射为 <--- ppn --- ppo --->
sn: segment number, pn:page number, po: page offset
若以 4K(limit) 为 1 个页表大小, 则下级页表首址为 段/页表中某项的值 << 12(2^12 = 4K)
- 以 vsn 为索引在进程段表中找到段表项, 获取段(页表)基址与段大小信息(item_value/limit): base = item_value << log2(limit)
- 以 vpn 为索引在进程页表(页表基址 = base 中找到页表项, 获取 ppn
- ppn << log2(limit) + vpo(ppo) 为实际物理地址
内存的特权级
0: 最高特权级, 3: 最低特权级
特权级检查
- CPL/RPL: 访问者特权级
- DRL: 段描述符/门描述符(中断/陷阱门)中保存的特权级, 表示被访问段/中断服务/陷阱的特权级
- CPL/RPL <= DRL e.g 0 < 3
特权级切换
Ring 0 to Ring 3
- interrupt/trap: push SS(RPL=3) -> ESP -> EFLAGS -> CS(RPL=3) -> EIP -> Error Code
- iret: pop above variables, move to ring 3
Ring 3 to Ring 0
特权级提升:
- interrupt/trap: stack switch
- push EFLAGS -> CS(RPL=0) -> EIP -> Error Code
- iret: pop above variables, move to ring 0
TSS
Task State Segment:
保存不同特权级的堆栈信息(SS/ESP)
全局描述符表中保存一个 TSS Descriptor(TSS base + TSS limit): allocate TSS memory -> init TSS -> fill TSS descriptor in GDT -> set TSS selector(task register)
虚拟内存管理
虚拟内存 = 物理内存 + 外存
Page Fault
- 虚拟地址越界: 访问不存在的虚拟地址
- 对只读地址进行写操作
- 访问未映射虚拟页(swap in/out)
- CPU 将产生异常的的线性地址(linear address) 存储在 CR2 寄存器中, 将 errorCode(bit2-访问权限异常,bit1-写异常,bit0-物理页不存在)压入中断栈
CR0: 处理器模式(实/保护/分段/分页模式); CR2: Page Fault Linear Address; CR3: Page-Directory Base Address Register
覆盖与交换
覆盖技术
Overlay:
将程序中相互独立的模块分成一组, 为每组按最大模块分配内存单元
交换技术
Swap:
将挂起进程的整个地址空间换出至外存(swap out), 将需用进程的整个地址空间换入至内存(swap in), 进程交替运行
虚拟页式存储管理
- 只将运行进程所必需页面装入内存, 其余页面至于外存
- 进程发生缺页异常时, 将所要求缺页装入内存: 选择目标物理页面 -> 无未占用物理页面, 则换出闲置物理页面(访问位) -> 装入物理内存,更新页表项 (换入逻辑地址与换出逻辑地址对应的页表项的驻留位/修改位/访问位/锁定位以及物理页号 ppn)
- 监控已经装入内存的页面, 及时将不需要页面换出至外存
标志位
- 驻留位: 此逻辑地址对应的页面在内存中
- 修改位: 此页面是否被修改过, 判定此页面换出时策略(写回外存/直接丢弃)
- 访问位: 此页面是否被读/写过, 判定此页面是否需要换出至外存
- 锁定位: 此页面不会被换出
页面置换算法
当出现缺页异常且物理内存已满时, 需要以页面置换算法为指导, 换出闲置物理页面, 换入所要求缺页, 并更新页表项:
- 尽可能减少物理页面的换入换出次数
- 只可交换映射到用户空间的物理页
- 当页表项中
PTE_P为 0 时, 对应高位地址表示扇区地址(而不是物理位移) - 换入时机: Page Fault 缺页; 换出时机: 积极/消极换出策略
局部置换算法
换入进程 A 的某个页面时, 只可换出进程 A 的某个页面: 为进程分配固定数目的页面
最远未用算法
Least Recently Used (LRU) Algorithm:
- 利用链表等线性结构维护页面访问时间, 队首为最近一次访问页面(每次访问一个页面后, 把它从线性结构中间抽出至队首), 队尾为最远一次访问页面
时钟算法
Clock Algorithm:
- 利用循环链表维护页面(指针指向最先换入内存的页面), 页表项访问位维护访问记录(访问后将访问位置 1)
- 缺页时, 从指针处开始查找页面进行置换: 若访问位为 0, 则进行置换; 若访问位为 1, 则将此页面访问位置 0, 继续查找未访问页面
- 改进: 增加修改位
| 指针扫描前 | 指针扫描后 |
|---|---|
| 访问位 修改位 | 访问位 修改位 |
| 0 0 | 置换 |
| 0 1 | 0 0 |
| 1 0 | 0 0 |
| 1 1 | 0 1 |
最不常用算法
Least Frequently Used (LFU) Algorithm:
- 利用链表等线性结构维护页面访问时间, 队首为最多访问次数页面(每次访问一个页面后, 访问次数+1, 并排序), 队尾为最少访问次数页面
全局置换算法
- 换入进程 A 的某个页面时, 可换出其他进程的某个页面: 为进程分配可变数目的页面
- 关键: 确定为不同进程分配的页面数目
- 抖动(thrashing): 进程过多, 导致大部分进程的常驻集<工作集, 缺页率较高
工作集算法
- 工作集(随时间动态变化集): 一个进程当前正在使用的逻辑页面集合,
WorkingSet(currentTime, workingSetWindow(访问时间窗口))
(cT - wSW, cT + wSW) - 根据工作集大小(逻辑页面集合), 为该进程分配常驻集(合适数目的物理页面集合): 若常驻集 > 工作集, 则缺页率较低
- 再额外维护一个类希 LRU 算法中的访存链表, 记录近期访问过的物理页面, 将其也加入常驻集
缺页率算法
当缺页频繁时, 缺页时将缺页的页面加入常驻集; 当缺页不频繁时, 缺页时将不属于工作集的页面移出常驻集
实现
- 为每个进程分配一个 vma 块, 模拟一个完整的物理内存
- vmas 按起始地址从小至大形成一个双向链表, 且地址空间没有任何交集
#define VM_READ 0x00000001
#define VM_WRITE 0x00000002
#define VM_EXEC 0x00000004
#define VM_USER (VM_READ | VM_WRITE | VM_EXEC)
typedef struct __mm {
list_entry_t mmap_list; // header of vmas' list
vma *mmap_cache; // current accessed vma(used for speed purpose)
pde_t *pgdir; // PDT for vmas
int map_count; // count of vmas
void *sm_priv; // private data for swap manager
} mm;
typedef struct __vma {
struct mm *vm_mm; // all vmas use the same PDT(page directory table)
uintptr_t vm_start; // start address of vma (align to PGSIZE)
uintptr_t vm_end; // end address of vma (align to PGSIZE)
uint32_t vm_flags; // flags of vma
list_entry_t vma_list; // doubly linked list: sort all vmas by start address
} vma;
中断
Interrupt Service Routine/Interrupt Quest:
- NMI 中断(Non Maskable Interrupt) 与 INTR 中断(可屏蔽中断)
- x86PC 中断控制芯片: 8259A PIC
中断进入
保护现场
- push PSW(Program State Word): (cs:eip + eflags)
- push PC(Program Counter)
- 中断向量表(将中断向量表对应的中断的 PSW(高 2 字节) 与 PC(低 2 字节) 先后替换原 PSW 与 PC)
- 系统堆栈
- 中断屏蔽码: n 位 2 进制数(n 为中断总数), 允许响应 n 号中断则该位置 1
程序状态字:
- 当前执行指令(eip)
- 当前指令执行情况
- 处理机所处状态
- 中断屏蔽码(程序在执行时应屏蔽的中断)
- 寻址方法/编址/保护键
- 响应中断的内容
中断实现
概述
- 硬件发生了某个事件后告诉中断控制器(PIC), 中断控制器汇报给 CPU
- CPU 从中断控制器处获取中断号, 根据中断号调用对应中断服务例程
- 处理完成后重新回到之前的执行流程
Interrupt 实现
- 发生中断, PIC 报告中断号给 CPU
- CPU 调用对应处理程序 irsr_x/irq_x
- irsr_x/irq_x 负责压入相关信息(中断号/错误码), 然后跳转至统一处理函数
common_stub common_stub: 压栈 -> 调用 fault_handler/req_handler -> 出栈- 进入 handler 后, 再根据中断号/错误码(结构体)以及栈帧信息(结构体), 进行实际处理(真正处理逻辑)
- 在进入 handler 之前, 都是通过汇编代码进行最简单的处理(压入相关信息), 将实际中断处理逻辑放在 C 语言中, 再辅以内联汇编, 可大大地提升中断处理程序的编写效率以及中断处理程序的处理能力
系统调用
- 保护系统安全, 提升可靠性与安全性
- 调用: 用户态, 执行: 管态/内核态
进程
资源分配单位:
- 独立性: 无副作用(确定性), 可重现
- 并发性(宏观并行, 微观串行): 提升效率, 共享资源, 高度模块化
进程特权级
- 处理机的态/处理机的特权级: 根据对资源和机器指令的使用权限, 将处理执行时的工作状态区分为不同的状态
- 管理(supervisor mode)/系统态: 使用全部机器指令(包括特权指令), 可使用所有资源, 允许访问整个内存区, 运行系统程序
- 用户态: 禁止使用特权指令(I/O 设备指令, 直接修改特殊寄存器指令, 改变机器状态指令), 不可直接取用资源与改变机器状态, 只可访问自己的存储区域, 运行用户程序
- 用户态切换至管态: 错误/异常状态(除 0/缺页), 外部中断(I/O), 系统调用, 这一过程是由硬件完成的
进程状态与生命周期
创建, 就绪(ready), 运行(running), 等待(wait/sleeping), 挂起(suspend: 进程由内存换出至外存), 结束(抢占, 唤醒): 进程优先级与剩余内存单元在一定程度上会影响进程状态
- 进程首先在 cpu 初始化或者 sys_fork 的时候被创建,当为该进程分配了一个进程控制块之后,该进程进入 uninit 态
- 当进程完全完成初始化之后,该进程转为 runnable 态
- 当到达调度点时,由调度器 sched_class 根据运行队列 rq 的内容来判断一个进程是否应该被运行, 即把处于 runnable 态的进程转换成 running 状态,从而占用 CPU 执行
- running 态的进程通过 wait 等系统调用被阻塞,进入 sleeping 态
- sleeping 态的进程被 wake up 变成 runnable 态的进程
- running 态的进程主动 exit 变成 zombie 态, 然后由其父进程完成对其资源的最后释放,子进程的进程控制块成为 unused
- 所有从 runnable 态变成其他状态的进程都要出运行队列(dequeue), 反之,被放入某个运行队列中(enqueue)
进程控制块
Process Control Block:
通过组织管理 PCB(链表/索引表) 来组织管理进程; 在进程创建/终止的同时, 生成/回收改进程的 PCB:
- 进程信息: 名字/pid/uid
- 链表信息: 父进程指针/所属队列指针(就绪队列/IO 等待队列/挂起队列)
- CPU 调度/运行时信息: eflags/cr3/状态
- 内存资源信息: 堆指针/栈指针/虚拟内存页面指针
- 上下文信息(用于进程/上下文切换时保存/恢复上下文): trap frame/context(register files)
进程通信
- 直接通信: send(proc, msg), receive(proc, msg)
shmctl() shm* - 间接通信: send(msg_que, msg), receive(msg_que, msg)
msgctl() msg*
线程
CPU 调度单位:
- 进程缺陷: 共享数据不便, 系统开销大
- 线程共享段表/共享库/数据/代码/环境变量/文件描述符集合/地址空间, 但拥有独立的堆/栈/通用寄存器
- 线程控制块(Thread Control Block)
- 用户线程与内核线程: 多为 1 对 1
IDLE Process
0 号内核线程:
- 工作就是不停地查询,直至有其他内核线程处于就绪状态, 令调度器执行那个内核线程
- IDLE 内核线程是在操作系统没有其他内核线程可执行的情况下才会被调用
- 在所有进程中,只有 IDLE (内核创建的第一个内核线程) 没有父进程
内核线程与用户进程
- 内核线程只运行在内核态
- 用户进程会交替运行在用户态和内核态(系统调用/外设中断/异常中断)
- 所有内核线程直接使用共同的内核内存空间, 拥有相同的内核虚拟地址空间(包括物理地址空间)
- 每个用户进程拥有单独的用户内存空间(虚拟内存单元)
Process 实现
Process Context
执行现场/执行上下文:
- 设置好执行现场后, 一旦调度器选择了 initproc 执行, 就需要根据 initproc->context 中保存的执行现场来恢复 initproc 的执行
- 通过 proc_run 和进一步的 switch_to 函数完成两个执行现场的切换,具体流程如下:
- 让 current 指向 next 内核线程 initproc
- 设置任务状态段 ts 中特权态 0 下的栈顶指针 esp0 为 next 内核线程 initproc 的内核栈的栈顶, 即 next->kstack + KSTACKSIZE
- 设置 CR3 寄存器的值为 next 内核线程 initproc 的页目录表起始地址 next->cr3
- 由 switch_to 函数完成具体的两个线程的执行现场切换, 即切换各个寄存器
Process Fork Function
- 分配并初始化进程控制块(alloc_proc 函数)
- 分配并初始化内核栈(setup_stack 函数)
- 根据 clone_flag 标志复制或共享进程内存管理结构(copy_mm 函数)
- 设置进程在内核(或用户态)正常运行和调度所需的中断帧和执行上下文(copy_thread 函数)
- 把设置好的进程控制块放入 hash_list 和 proc_list 两个全局进程链表中
- 把进程状态设置为“就绪”态
- 设置返回码为子进程的 id 号
fork() 的主要行为:
- 申请 pid 与进程结构
- 设置 ppid 为父进程的 pid
- 复制用户相关的字段, 如 p_pgrp/p_gid/p_ruid/p_euid/p_rgid/p_egid
- 复制调度相关的字段, 如 p_cpu/p_nice/p_pri
- 复制父进程的文件描述符 (p_ofile), 并增加引用计数
- 复制父进程的信号处理例程 (p_sigact)
- 通过 vm_clone(), 复制父进程的地址空间(p_vm)
- 复制父进程的寄存器状态 (p_context)
- 复制父进程的中断上下文, 并设置 tf->eax 为 0, 使 fork()在子进程中返回 0。
Execution function
exec() 的主要行为:
- 读取文件的第一个块, 检查 Magic Number 是否正确
- 保存参数(argv)到临时分配的几个物理页, 其中的每个字符串单独一页
- 清空旧的进程地址空间(vm_clear()), 并结合可执行文件的 header, 初始化新的进程地址空间(vm_renew())
- 将 argv 与 argc 压入新地址空间中的栈
- 释放临时存放参数的几个物理页
- 关闭带有 FD_CLOEXEC 标识的文件描述符
- 清理信号处理例程
- 通过
_retu()返回用户态
处理机调度
Schedule:
- 从就绪队列中挑选下一个占用 CPU 的进程(挑选进程的内核函数)
- 从多个可用 CPU 中挑选使用 CPU 资源
调度时机
- 进程停止运行, 进入等待/挂起/终止状态
- 进程的中断请求完成时, 由等待状态进入就绪状态, 准备抢占 CPU 资源(准备从内核态返回用户态)
六大调度时机
- proc.c::do_exit 用户线程执行结束,主动放弃 CPU 控制权
- proc.c::do_wait 用户线程等待子进程结束,主动放弃 CPU 控制权
- proc.c::init_main
- initproc 内核线程等待所有用户进程结束,如果没有结束,就主动放弃 CPU 控制权
- initproc 内核线程在所有用户进程结束后,让 kswapd 内核线程执行 10 次,用于回收空闲内存资源
- proc.c::cpu_idle idleproc 内核线程的工作就是等待有处于就绪态的进程或线程,如果有就调用 schedule 函数
- sync.h::lock 在获取锁的过程中,如果无法得到锁,则主动放弃 CPU 控制权
- trap.c::trap 如果在当前进程在用户态被打断,且当前进程控制块的成员变量 need_resched 设置为 1,则当前线程会放弃 CPU 控制权
调度策略
算法目标
- CPU 有效使用率
- 吞吐量 (高带宽): 单位时间内完成进程数量
- 等待时间 (低延迟): 进程在就绪队列等待总时间
- 周转时间 (低延迟): 进程从初始化到结束总时间
- 响应时间 (低延迟): 从提交请求到产生响应总时间
先来先服务算法
First Come First Served (FCFS):
- 依次执行就绪队列中的各进程(先进入就绪队列先执行)
- CPU 利用率较低
短进程优先算法
Shortest Process Next/Shortest Remaining Time:
- 优先执行周转耗时/剩余耗时最短的进程
- 若短进程过多, 则导致长进程一直无法执行
最高响应比优先算法
Highest Response Ratio Next:
- R = (waitTime + serviceTime) / serviceTime: 已等待时间越长, 优先级上升
- 修正短进程优先算法的缺点
时间片轮转算法
Round Robin:
- 在 FCFS 基础上, 设定一个基本时间单元, 每经过一个时间单元, 轮转至下一个先到进程(并进行循环轮转)
- 额外的上下文切换
- 时间片合适大小: 10 ms
多级队列调度算法
MQ:
- 将就绪队列分成多个独立子队列, 每个队列可采取不同调度算法
- 前台交互队列使用时间片轮转算法, 后台 IO 队列使用先来先服务算法
- 队列间使用时间片轮转算法
多级反馈队列算法
MLFQ:
- 优先级高的子队列时间片小, 优先级低的子队列时间片大
- CPU 密集型进程(耗时高)优先级下降很快
- IO 密集型进程(耗时低)停留在高优先级
同步互斥
- 互斥 (Mutual Exclusion)
- 死锁 (Deadlock)
- 饥饿 (Starvation)
临界区的访问原则
- 空闲则入
- 忙则等待
- 有限等待
基于软件方法的同步互斥
int turn; // 表示谁该进入临界区
bool flag[]; // 表示进程是否准备好进入临界区
// 对于 2 个线程的情况
// Peterson Algorithm
// 线程 i
flag[i] = true;
turn = j; // 后设置 turn 标志的进程不可进入临界区, 会在 while 循环进行等待
while (flag[j] && turn == j) ;
...// critical section
flag[i] = false;
// Dekkers Algorithm
// 线程 i
turn = 0;
flag[] = {false};
do {
flag[i] = true;
while (flag[j] == true) {
if (turn != i) {
flag[i] = false;
while (turn != i) ;
flag[i] = true;
}
}
// critical section
turn = j;
flag[i] = false;
} while (true);
高级抽象的同步互斥
利用原子操作实现互斥数据结构
Lock and Semaphore
struct lock/semaphore {
bool locked/sem = n; // n: 并发数/可用资源数
wait_queue q;
void acquire/prolaag() {
locked/sem--;
if (locked/sem < 0) sleep_and_enqueue(this_thread);
};
void release/verhoog() {
locked/sem++;
if (locked/sem <= 0) wakeup_and_dequeue(other_thread);
};
};
Monitor
- 与 semaphore 相反, 初始 0,
wait(++ && sleep),signal(-- && wakeup) - 管程内可以中断执行, 并 notify 其他等待线程
死锁
非抢占持有互斥循环等待
Mutex
Mutual Exclusion and Spinlock
- 当资源等待的时间较长, 用互斥锁让线程休眠, 会消耗更少的资源.
- 当资源等待的时间较短时, 使用自旋锁将减少线程的切换, 获得更高的性能.
Readers–writer Lock
- 读写锁允许同一时刻被多个读线程访问.
- 写线程访问时, 所有的读线程和其他的写线程都会被阻塞.
- 读读不互斥, 读写互斥, 写写互斥.
Prolaag and Verhoog
Prolaag Semaphore
- 关中断.
- 判断当前信号量的 value 是否大于 0.
- 如果是> 0, 则表明可以获得信号量, 故让 value 减一, 并打开中断返回.
- 如果不是> 0, 则表明无法获得信号量, 故需要将当前的进程加入到等待队列中, 并打开中断, 然后运行调度器选择另外一个进程执行.
- 如果被 V 操作唤醒, 则把自身关联的 wait 从等待队列中删除 (此过程需要先关中断, 完成后开中断).
Verhoog Semaphore
- 关中断.
- 如果信号量对应的 wait queue 中没有进程在等待, 直接把信号量的 value 加一,然后开中断返回.
- 如果有进程在等待且进程等待的原因是 semaphore 设置的,
则调用
wakeup_wait函数将 wait queue 中等待的第一个 wait 删除, 且把此 wait 关联的进程唤醒, 最后开中断返回.
管程
管程由四部分组成:
- 管程内部的共享变量(mutex): 一个二值信号量, 是实现每次只允许一个进程进入管程的关键元素, 确保了互斥访问性质.
- 管程内部的条件变量:
通过执行
wait_cv, 会使得等待某个条件 C 为真的进程能够离开管程并睡眠, 且让其他进程进入管程继续执行; 而进入管程的某进程设置条件 C 为真并执行signal_cv时, 能够让等待某个条件 C 为真的睡眠进程被唤醒, 从而继续进入管程中执行. - 管程内部并发执行的进程.
- 对局部于管程内部的共享数据设置初始值的语句.
- 成员变量信号量
next: 配合进程对条件变量 cv 的操作而设置的, 由于发出signal_cv的进程 A 会唤醒睡眠进程 B, 进程 B 执行会导致进程 A 睡眠, 直到进程 B 离开管程, 进程 A 才能继续执行, 这个同步过程是通过信号量next完成. - 整形变量
next_count: 表示由于发出signal_cv而睡眠的进程个数.
typedef struct monitor{
// the mutex lock for going into the routines in monitor,
// should be initialized to 1
semaphore_t mutex;
// the next semaphore is used to down the signaling proc itself,
// and the other OR woke up
semaphore_t next;
int next_count; // the number of of sleepy signaling
proc condvar_t *cv; // the conditional variable in monitor
} monitor_t;
Conditional Variable
- wait_cv: 被一个进程调用, 以等待断言 Pc 被满足后该进程可恢复执行. 进程挂在该条件变量上等待时, 不被认为是占用了管程
- signal_cv:被一个进程调用, 以指出断言 Pc 现在为真, 从而可以唤醒等待断言 Pc 被满足的进程继续执行
- 信号量 sem: 用于让发出 wait_cv 操作的等待某个条件 C 为真的进程睡眠, 而让发出 signal_cv 操作的进程通过这个 sem 来唤醒睡眠的进程
- count: 表示等在这个条件变量上的睡眠进程的个数
- owner: 表示此条件变量的宿主是哪个管程
typedef struct condvar{
// the sem semaphore is used to down the waiting proc,
// and the signaling proc should up the waiting
semaphore_t sem;
proc int count; // the number of waiters on
condvar monitor_t * owner; // the owner(monitor) of this conditional variable
} condvar_t;
文件系统
File System:
- 分配文件磁盘空间: 分配与管理
- 管理文件集合: 定位, 命名, 文件系统结构
- 数据可靠和安全: 持久化保存, 防止数据丢失(系统崩溃时)
- 基本操作单位: 数据块
- 文件访问模式: 顺序访问/随机访问/索引访问
- 文件系统种类: 磁盘/数据库/日志/网络/分布式/虚拟文件系统
文件组成
- 文件头: 文件属性(名称/类型/大小/权限/路径/创建者/创建时间/最近修改时间)
- 文件头: 文件存储位置与顺序
- 文件体: 实际字节序列
文件系统基本数据结构
Super Block -> Directory Entry -> vnode/inode
文件卷控制块
Super Block:
- 每个文件系统只有一个控制块
- 描述该文件系统全局信息: 数据块(大小等信息), 空余块信息, 文件指针/引用计数
目录项
Directory Entry:
- 目录是一类特殊的文件: 其内容为文件索引表(文件名/文件指针), 内部采取哈希表存储
- 目录与文件构成树状结构
- 每个目录项属于一个目录, 一个目录可有多个目录项
- 保存目录相关信息: 指向文件控制块, 父目录/子目录信息
文件控制块
vnode/inode:
- 每个文件有一个文件控制块
- 保存该文件详细信息: 访问权限, 所属者/组, 文件大小, 数据块位置(索引)
文件描述符
操作系统在打开文件表中维护的打开文件状态与信息:
- 文件指针: 最近一次读写位置
- 文件打开计数(引用计数): 引用计数为 0 时, 回收相关资源
- 文件磁盘位置
- 访问权限
打开文件表
- 系统打开文件表: 保存文件描述符
- 进程打开文件表: 指向系统打开文件表某项, 并附加额外信息
文件分配
- 分配方式: 连续分配, 琏式分配, 索引分配
- 琏式索引分配: 琏式链接多个索引块
- 多级索引分配: 索引分配 + 多级琏式索引块
空闲空间管理
- bit 位图, 链表, 琏式索引: 保存空闲数据块位置与顺序
冗余磁盘阵列
Redundant Array of Inexpensive Disks (RAID):
- RAID-0: 磁盘条带化
- RAID-1: 磁盘镜像(冗余拷贝), 提高可靠性
- RAID-4: 带奇偶校验(校验和)的磁盘条带化, 提高可靠性
- RAID-5: 带分布式奇偶校验的磁盘条带化, 减少校验和所在物理磁盘的读写压力
- RAID-6: 每组条带块有两个冗余块, 可以检查到 2 个磁盘错误
FS 实现
FS Mount
sfs_do_mount函数中:
- 完成了加载位于硬盘上的 SFS 文件系统的超级块 superblock 和 freemap 的工作 l
- 在内存中有了 SFS 文件系统的全局信息
FS Index
- 对于普通文件,索引值指向的 block 中保存的是文件中的数据
- 对于目录,索引值指向的数据保存的是目录下所有的文件名以及对应的索引节点所在的索引块(磁盘块)所形成的数组
FS Node
内存 inode 包含了 SFS 的硬盘 inode 信息, 而且还增加了其他一些信息, 这属于是便于进行是判断否改写、互斥操作、回收和快速地定位等作用. 一个内存 inode 是在打开一个文件后才创建的, 如果关机则相关信息都会消失. 而硬盘 inode 的内容是保存在硬盘中的, 只是在进程需要时才被读入到内存中, 用于访问文件或目录的具体内容数据.
struct inode {
union {
//包含不同文件系统特定inode信息的union成员变量
struct device __device_info; //设备文件系统内存inode信息
struct sfs_inode __sfs_inode_info; //SFS文件系统内存inode信息
} in_info;
enum {
inode_type_device_info = 0x1234,
inode_type_sfs_inode_info,
} in_type; //此inode所属文件系统类型
atomic_t ref_count; //此inode的引用计数
atomic_t open_count; //打开此inode对应文件的个数
struct fs *in_fs; //抽象的文件系统,包含访问文件系统的函数指针
const struct inode_ops *in_ops; //抽象的inode操作,包含访问inode的函数指针
};
struct inode_ops {
unsigned long vop_magic;
int (*vop_open)(struct inode *node, uint32_t open_flags);
int (*vop_close)(struct inode *node);
int (*vop_read)(struct inode *node, struct iobuf *iob);
int (*vop_write)(struct inode *node, struct iobuf *iob);
int (*vop_getdirentry)(struct inode *node, struct iobuf *iob);
int (*vop_create)(
struct inode *node,
const char *name,
bool excl,
struct inode **node_store);
int (*vop_lookup)(struct inode *node, char *path, struct inode **node_store);
……
};
Device
利用 vfs_dev_t 数据结构,
就可以让文件系统通过一个链接 vfs_dev_t 结构的双向链表找到 device 对应的 inode 数据结构,
一个 inode 节点的成员变量 in_type 的值是 0x1234,
则此 inode 的成员变量 in_info 将成为一个 device 结构。
这样 inode 就和一个设备建立了联系,这个 inode 就是一个设备文件
ELF File Format
#include "common.h"
#include <stdlib.h>
#include <elf.h>
char *exec_file = NULL;
static char *strtab = NULL;
static Elf32_Sym *symtab = NULL;
static int nr_symtab_entry;
void load_elf_tables(int argc, char *argv[]) {
int ret;
Assert(argc == 2, "run NEMU with format 'nemu [program]'");
exec_file = argv[1];
FILE *fp = fopen(exec_file, "rb");
Assert(fp, "Can not open '%s'", exec_file);
uint8_t buf[sizeof(Elf32_Ehdr)];
ret = fread(buf, sizeof(Elf32_Ehdr), 1, fp);
assert(ret == 1);
/* The first several bytes contain the ELF header. */
Elf32_Ehdr *elf = (void *)buf;
char magic[] = {ELFMAG0, ELFMAG1, ELFMAG2, ELFMAG3};
/* Check ELF header */
assert(memcmp(elf->e_ident, magic, 4) == 0); // magic number
assert(elf->e_ident[EI_CLASS] == ELFCLASS32); // 32-bit architecture
assert(elf->e_ident[EI_DATA] == ELFDATA2LSB); // little-endian
assert(elf->e_ident[EI_VERSION] == EV_CURRENT); // current version
assert(elf->e_ident[EI_OSABI] == ELFOSABI_SYSV || // UNIX System V ABI
elf->e_ident[EI_OSABI] == ELFOSABI_LINUX); // UNIX - GNU
assert(elf->e_ident[EI_ABIVERSION] == 0); // should be 0
assert(elf->e_type == ET_EXEC); // executable file
assert(elf->e_machine == EM_386); // Intel 80386 architecture
assert(elf->e_version == EV_CURRENT); // current version
/* Load symbol table and string table for future use */
/* Load section header table */
uint32_t sh_size = elf->e_shentsize * elf->e_shnum;
Elf32_Shdr *sh = malloc(sh_size);
fseek(fp, elf->e_shoff, SEEK_SET);
ret = fread(sh, sh_size, 1, fp);
assert(ret == 1);
/* Load section header string table */
char *section_header_string_table = malloc(sh[elf->e_shstrndx].sh_size);
fseek(fp, sh[elf->e_shstrndx].sh_offset, SEEK_SET);
ret = fread(section_header_string_table sh[elf->e_shstrndx].sh_size, 1, fp);
assert(ret == 1);
int i;
for(i = 0; i < elf->e_shnum; i ++) {
if(sh[i].sh_type == SHT_SYMTAB &&
strcmp(section_header_string_table + sh[i].sh_name, ".symtab") == 0) {
/* Load symbol table from exec_file */
symtab = malloc(sh[i].sh_size);
fseek(fp, sh[i].sh_offset, SEEK_SET);
ret = fread(symtab, sh[i].sh_size, 1, fp);
assert(ret == 1);
nr_symtab_entry = sh[i].sh_size / sizeof(symtab[0]);
}
else if(sh[i].sh_type == SHT_STRTAB &&
strcmp(section_header_string_table + sh[i].sh_name, ".strtab") == 0) {
/* Load string table from exec_file */
strtab = malloc(sh[i].sh_size);
fseek(fp, sh[i].sh_offset, SEEK_SET);
ret = fread(strtab, sh[i].sh_size, 1, fp);
assert(ret == 1);
}
}
free(sh);
free(section_header_string_table ;
assert(strtab != NULL && symtab != NULL);
fclose(fp);
}
设备管理详解
- CPU 一般都是通过寄存器的形式来访问外部设备
- 外设的寄存器通常包括控制寄存器、状态寄存器与数据寄存器三类, 分别用于发送命令/读取状态/读写数据.
CGA EGA and ChromaText Video Buffer
在内存的低 1MB 中, 有许多地址被映射至外部设备, 其中就包含文字显示模块(显卡控制显示器):
- 从 0xB8000 开始, 每 2 个字节表示屏幕上显示的一个字符(80 x 25)
- 前一个字节为 字符 ASCII 码, 后一个字节为 字符颜色和属性的控制信息 (back_twinkle, back_r, back_g, back_b, front_light, front_r, front_g, front_b)
Input and Output
调用 io_delay() 函数: 对于一些老式总线的外部设备, 读写 I/O 端口的速度若过快就容易出现丢失数据的现象
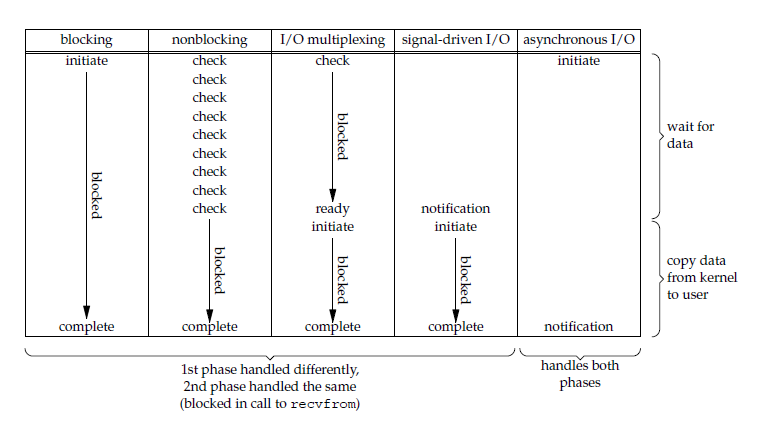
实践
工具
Bochs
Installation
wget
\ http://sourceforge.net/projects/bochs/files/bochs/2.5.1/bochs-2.5.1.tar.gz/download
\ -O bochs.tar.gz
tar -xvfz bochs.tar.gz
cd bochs-2.5.1
./configure --enable-debugger --enable-debugger-gui --enable-disasm --with-x --with-term
make
sudo cp ./bochs /usr/bin/bochs-dbg
Config
# BIOS与VGA镜像
romimage: file=/usr/share/bochs/BIOS-bochs-latest
vgaromimage: file=/usr/share/bochs/VGABIOS-lgpl-latest
# 内存大小
megs: 128
# 软盘镜像
floppya: 1_44=bin/kernel.images, status=inserted
# 硬盘镜像
ata0-master: type=disk, path="bin/rootfs.images",
\ mode=flat, cylinders=2, heads=16, spt=63
# 引导方式(软盘)
boot: a
# 日志输出
log: .bochsout
panic: action=ask
error: action=report
info: action=report
debug: action=ignore
# 杂项
vga_update_interval: 300000
keyboard_serial_delay: 250
keyboard_paste_delay: 100000
mouse: enabled=0
private_colormap: enabled=0
fullscreen: enabled=0
screenmode: name="sample"
keyboard_mapping: enabled=0, map=
keyboard_type: at
# 符号表(调试用)
debug_symbols: file=main.sym
# 键盘类型
keyboard_type: at
Run
bochs -q -f .bochsrc
- b,vb,lb 分别为物理地址、虚拟地址、逻辑地址设置断点
- c 持续执行,直到遇到断点或者错误
- n 下一步执行
- step 单步执行
- r 显示当前寄存器的值
- sreg 显示当前的段寄存器的值
- info gdt, info idt, info tss, info tab 分别显示当前的 GDT、IDT、TSS、页表信息
- print-stack 打印当前栈顶的值
- help 显示帮助
GNU ld
ENTRY(kmain)
SECTIONS {
__bios__ = 0xa0000; # 绑定BIOS保留内存的地址到__bios__
vgamem = 0xb8000; # 绑定vga缓冲区的地址到符号vgamem
.text 0x100000 : { # 内核二进制镜像中的.text段(Section),从0x100000开始
__kbegin__ = .; # 内核镜像的开始地址
__code__ = .;
bin/entry.o(.text) bin/main.o(.text) *(.text); # 将bin/entry.o中的.text段安排到内核镜像的最前方
. = ALIGN(4096); # .text段按4kb对齐
}
.data : {
__data__ = .;
*(.rodata);
*(.data);
. = ALIGN(4096);
}
.bss : {
__bss__ = .;
*(.bss);
. = ALIGN(4096);
}
__kend__ = .; # 内核镜像的结束地址
}
Memory Management Tools
perf
trace
vmstat
check usage of virtual memory and swap region
vmstat 2
pmap
check detailed usage of memory
pmap PID
Memory Hot Plug
TCMalloc
Google TCMalloc